How to Check for Duplicate Content on Website?
We’re initially focused on providing you with quality backlinks. But not everyone takes into account that the quality of referred pages is important as well. Our research shows that one of the most common on-page mistakes is duplicated pages. In this regard, we simply can’t ignore the subject of duplicate pages identification. We’ll consider how to check for duplicate content manually and use the most popular instruments.

Why do you need to search for duplicate content?
On-page SEO is one of the most important components in the successful promotion of the website. Sites quite often have problems with duplicate pages, which as a rule significantly lower the results of the promotion. In this video, a former head of the webspam team in Google Matt Cutts tells how Google handles duplicate content and what negative effects it has on rankings from an SEO perspective.
The presence of internal duplicate pages can lead to errors of indexing and even nullify the results of the promotion. E.g., if a page has promoted doubles, one of them can replace an original page in SERPs after the next update. This is usually accompanied by significant subsidence position, since a double, unlike the promoted page, has no reference weight (as it has no backlinks). LinksManagement met a lot of different variants of internal duplicates of various complexity, but still, there was no problem we couldn’t solve. The main thing is not to delay, as over time pages fall out of the index and a website loses traffic.
Reasons for content duplication

Complete and partial doubles
- Complete doubles are pages with exactly the same content, which have different URL-addresses. For example, the page for printing and its normal original page with sessions identifiers, the same page with different extensions (.html, .php, .htm). Most of the doubles are generated by site engines, but also there are those that occur because of the carelessness of webmasters. Complete duplicates often appear after replacing a site design or structure: all pages get new URL-addresses, but the old address still works, and, as a result, each page is available in 2 different URLs. The other causes are: URL with GET parameters, incorrectly configured 404 page, URL in different registers, addresses with or without “/” at the end of URL, the same content for the first pagination and category pages (while they have different addresses), a 302 redirect.
- Partial doubles are pages with a very similar content. They occur in the case when page content consists of only one picture, and the rest is doorway blocks, page headings with a description of a product by only one sentence, etc. The other case is quite common for online shops, where the same goods are sometimes sorted by various indicators.
Why are duplicate pages dangerous?
- Site indexing getting worse. If your project has several thousand pages, and each of them has one double, a volume of the site “blows up” in 2 times. But what if you create more than one double? A rhetorical question.
- Incorrect distribution of backlink weight. Sometimes doubles appear as a result of incorrect internal linking. A duplicate can be considered as more important than the basic version of the page. Moreover, behavioral factors are also measured for the duplicate page.

- Changing of a relevant page in SERPs. Search algorithms can consider a double as a more relevant to a correspondent search query. Pages change in search results is often accompanied by a significant position decrease.
- Loss of external reference weight. When users got interested in your product or article, they sometimes share it with others via social buttons or even manually by putting links. If a target product was on a duplicate page, then a user will refer to it, and you lose that natural link.
How to avoid duplicate website content?
The way of getting rid of duplicates depends on how doubles appeared on a web source and whether there is a need to leave them in the index (e.g., if it is a product category or gallery).
- “Disallow” in Robots.txt. “Disallow” is used to disable the indexing of pages by search robots and to remove them from the database of already indexed pages. This is the best option to fight against doubles if duplicate pages are placed in concrete directories, or if URL structure allows closing many doubles at once. E.g., if you want to close all the pages with search results on a site, which are located in the www.mysite.com/search/, prescribe Disallow: /search/. If the sign “?” In a session ID, you can prevent the indexing of all pages containing the sign, prescribing Disallow: / * ?. This way you prohibit indexing of complete duplicates (pages for printing, pages of session IDs, pages for search through a site, etc.)
- “rel = canonical” tag. It’s used to indicate to robots which page of the group of doubles should participate in the search. This page is called canonical. To specify the canonical page, you need to prescribe its URL on the “secondary” pages: link rel=”canonical” href=”http://www.mysite.com/main-page.html”. This method is great when there are many doubles that can’t be closed in Robots.txt at once.

- 301 redirect. It’s used to redirect users and SE bots. Apply this method if some of the pages changed their URLs as a result of the engine change, and the same page is available by the old and the new URL. 301 redirect signals the search bots that a page has changed the address forever, so the weight of an old page transfers to a new one. You can configure a redirect in the “.htaccess” file: Redirect 301 /category/old-page.html http://www.mysite.com/category/new-page.html. You can set up a mass redirect from the pages of one type to another, but only in case of the same URL structure.
- Creative approach to the problem.
- There are cases when a page, showing signs of a duplicate, does contain useful info. In such case, you can add content or make it unique.
- Sometimes it happened that pages with a description in the same product category are very similar to each other. It’s impossible to make them unique or close them from indexing (as it decreases a content part). Then you can add some interesting unit to the page: reviews, a list of differences, etc.
- If different categories show the same goods or services, you can either not display announcements on the pages, or reduce them to a minimum and automatically change descriptions, depending on the categories for which the product is displayed.
How to detect duplicate content issues using Google?
- Go to the Google Advanced Search page and fill in all the required fields. As a result, you get a test site indexing according to the specified part of its text. Note that Google also indexes inaccurate doubles.
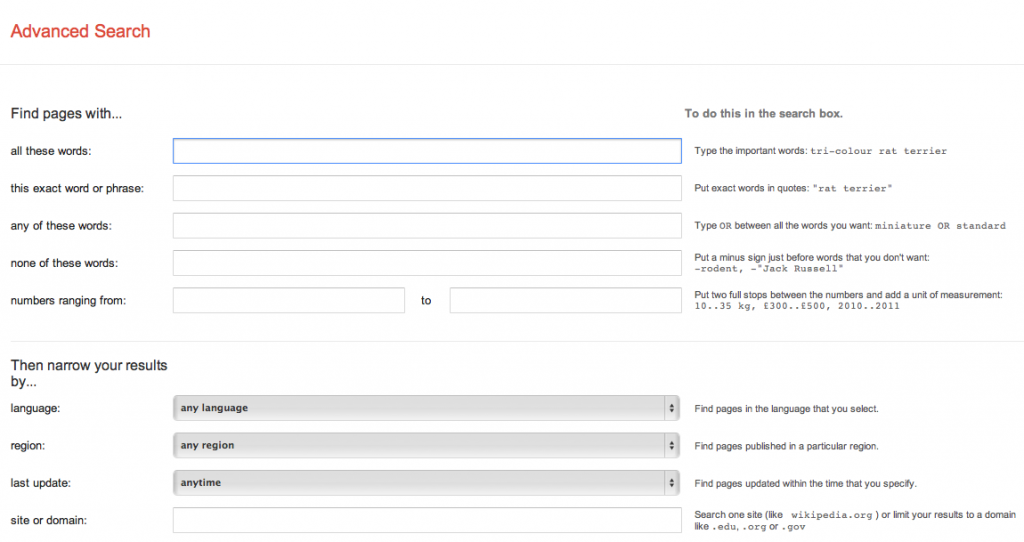
The same results can be obtained just with a simple Google search.
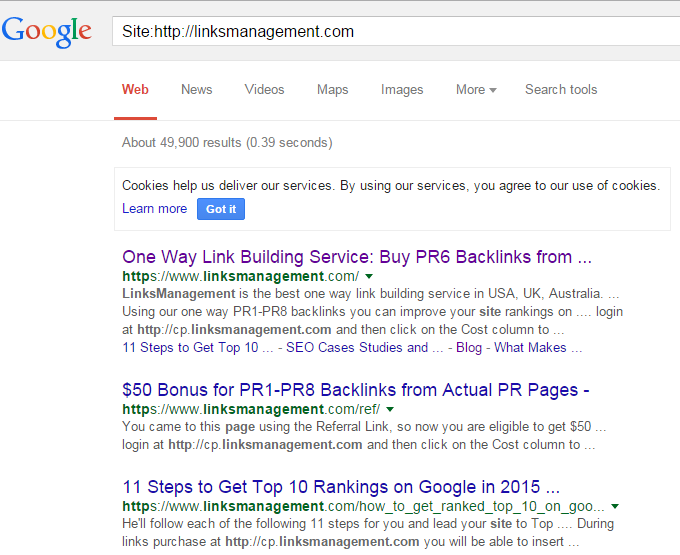
- Search by special request. Using Advanced Search, you’ll easily find all duplicates of a given text. But what if doubles don’t contain text (e.g., if they were created by improperly working pattern that shows a picture on a duplicate page)? Use the next method: using a special operator “Site:http://mysite.com “, we ask all our indexing of the site and manually looking for doubles. When we put a main page in the operator, we get a list of site pages indexed by the search robot:
And if you put the address of a particular page, you get a list of indexed duplicates of this page:
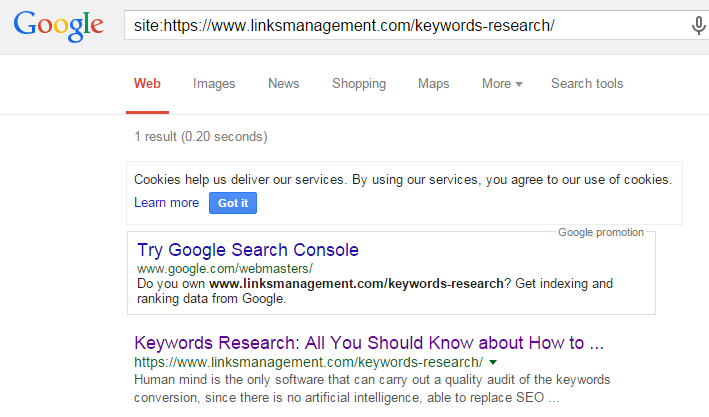
If there were duplicates, you would see “show hidden results” button.
Duplicate content detection using GWT
Go to the GWT toolbar, select the tab “Search Appearance”->”HTML Improvements”. Use sections “Duplicate meta descriptions” and “Duplicate title tags”.
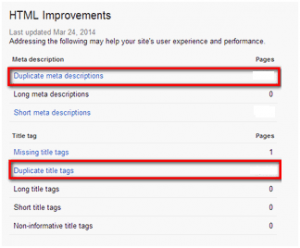
Duplicate pages usually have the same content and metadata. After analyzing the list of pages displayed in these tabs, you can easily identify such duplicates. We recommend you to check periodically the above toolbars for new errors.
Duplicate content checker software
- Grammarly Online Plagiarism Checker. Algorithms for this SEO duplicate content checker tool were developed by the world’s leading linguists.
- Grammar checking and elimination of errors. Checker corrects more than 250 most popular grammatical mistakes, together with spelling errors and vocabulary usage.
- An extension that works on all sites, including Gmail, Facebook, Tumblr, Twitter, LinkedIn, etc.
- Enhanced meaning and clarity.
- Increasing writing skills.
Plagiarism is a free to use complex tool, useful both for optimizers and content writers.
- Plagium. This is online duplicate content issue checker. To use it, just type or paste or text into the box. However, it has a limit of 5,000 characters for free use. If you exceed the limit, you pay 4 ¢ per page when using the “Quick Search” option, 8 ¢ per page – “Deep Search”, and 0.5 ¢ per page for “File Comparison”.
- Copyscape Premium
- Just copy and paste your text, or use URL.
- Ability to check up to 10 thousand pages at once.
- Ability to work with a team of editors.
- Checking for doubles within your content.
- Plagiarism checker. The program allows checking a document or a webpage for plagiarism.
- Virante Duplicate Content>. This is a website duplicate content finder that:
- Detects supplemental pages.
- Detects incorrect 404 pages.
- Diagnoses common content issues by checking headers and current Google cache.
- CopyGator. This is a service for checking RSS feed and finding out the exact time of content copying. The tool automatically notifies you when your posts got copied by someone. All the info you can see on a special page. The service is free.
- Plagiarisma. It’s a duplicate page checker useful for teachers, students, scholars, and optimizers, of course. The advantage of the tool is that it works on Android, Windows, BlackBerry and Web. Plagiarisma supports Google Books, Google Scholar, Babylon, Yahoo, and Google.
- PlagSpotter.
- 8034 daily URL checks.
- 858 daily users.
- Ability to find those who steal your content.
- Get an accurate % of plagiarism together with a list of sources.
- Automatically monitoring of selected ULRs.
- Protection of your website against content stealing.
- Allows to avoid SEO duplicate content penalty from Google.
Video walkthrough:
The service has Basic and Pro ($10 a month) packages, which differs from each other by the next features:
- Protection badges.
- Takedowns.
- Image WaterMarking.
- Certificate Management.
- Copyright protection tools.
- Plugins.
2 tips about how to set up and organize your site without creating duplicate content
- Always use “rel = ‘canonical'” meta tag on the pages of posts and static pages. When using cross-posting, try not to give the full article to the resource. Shorten it up to 50%. Put 2-3 backlinks with different anchors to the initial source. If it is possible to change the meta tags on a cross-posting resource, remove the “rel = ‘canonical'”.
- If you place an article on external resources and there is no possibility to make it unique, change at least some of the paragraphs. And again, be sure to put backlinks. Many thieves copy the content using special scripts, and, therefore, the links are copied together with a text.
Two of duplicate content myths
- A link with http://www.mysite.com/page.html# anchor creates duplicate content for SEs. It is not true, because this anchor is just a positioning of the page in the browser window when you click on the link, and it is not a dynamic parameter. SEs have long learned to distinguish the “anchor” from the dynamic parameters of links. Therefore, the use of links like “Read more” is more than safe.

- link rel = ‘canonical’ href = ‘http://www.mysite.com/page.html’ /meta tag will save your life. Unfortunately, this is not always true. Imagine a situation where you created the article, but someone stole it for an hour (for example, using your RSS) and placed in a new page, using rel = ‘canonical’. If your website rankings are about the same, the site to which crawler will come first will be considered as the original source. There is no one hundred percent solution of this problem. This meta tag rather helps to remove duplicate content within a single resource.
Conclusion
Duplicate content negatively affects site positions. To be successful, we strongly recommend you to carry out a thorough check and timely find duplicate content in ways that are listed above.
Enter URL & See What We Can Do Submit the form to get a detailed report, based on the comprehensive seo analysis.