The Importance of a Robots.txt File for Your SEO
On August 30, 2018, robots.txt celebrated its 25 years anniversary. Not all webmasters were happy with that fact, but only those who know how to configure robots.txt properly. At the beginning of 90s, websites didn’t have such a powerful bandwidth, so the situation when a website could not cope with the influx of crawlers was quite common… A lot has happened since that time, but robots.txt still has not lost its relevance. Now it is time to dispel the mystery of using the Robots meta tag elder brother. Here we go!

Robots.txt file tells crawlers if they are permitted to scan and index, or must ignore various site parts. This text file should always be named as robots.txt, in low letters, and be placed in a root directory. To check whether Googlebot has access to the file, you have to enter its URL-address to a browser.
For example, https://LinksManagement.com/robots.txt
Our Robots.txt protocol is:
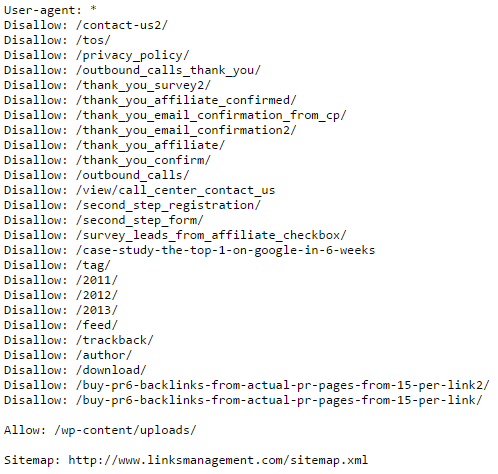
Does my site really need robots.txt?
Very often, our clients ask us about the importance of robots.txt file for a website as a whole in terms of search engines optimization. And there is a definite positive answer on the question whether you need robots.txt or not. Starting from 1994 this file allows site owners to communicate with SEs using a language they understand. Robots.txt not only tells SEs what they have to index but also provides them with the address of XML sitemap for more thorough scanning and correcting webpages rankings.
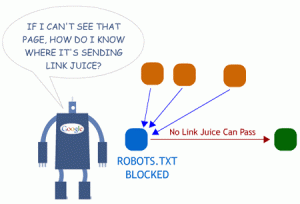
Of course, the absence of this feature will not stop SEs – they will continue to meticulously scan every web page for its subsequent indexation – but we strongly recommend you to get robots.txt and configure it to improve your search results. A fortiori, creation a robots.txt file will not take you more than a quarter of an hour.
A small digression: sitemap.xml installation
Sitemap.xml contains a list of site pages and instructions to search engines on how to visit these pages. The existence of such a file improves site indexing.
The creation of sitemap.xml on WordPress is quite simple, as there are several plug-ins for this purpose. Google XML Sitemaps ( is the most famous of them (note: you may not find the file in your site directory, as the plug-in creates a virtual file when assessing to it). By setting options, available in Google XML Sitemaps, you’ll allow Google and Bing to know the last changes.
So, the short brief on installing Sitemap is over, let’s get back to the previous discussion.
Google’s recommendation on robots.txt optioning
Google offers its own instrument for checking robots.txt options on GWT. Sure, you have to be authorized to use GWT. The checking procedure is the next:
- Select your site in GSC and pass to the tool. Syntax and logic errors in robots.txt will be highlighted, and their number will be indicated under the editing window.
- Specify the desired URL into a box at the bottom of the page.
- Select the robot in drop-down menu to the right.
- Click Check.
- You’ll see “available” or “unavailable” status. In the first case, Google’s robots can navigate to your address, in the second – they can’t.
- If necessary, make changes to the menu and run the test again. Attention: these fixes are not automatically included in robots.txt.
- Copy the modified content and add it to the file on your server.
Limitations of robots.txt
- The above instructions are recommendations only. Googlebot and most of other SEs follow the given instructions, but some systems can ignore them. To protect info from the robots use some advanced ways like passwords.
- Each crawler uses its own processing algorithm. The specific interpretation depends on the configuration of the robot.
- txt settings do not affect links from other sites. Google bot will not directly index the file content, but it will be able to find these pages using incoming backlinks. Therefore, Google search may show URL and other public inform (e.g. links text). To completely eliminate the appearance of URL in Google search, use robots.txt along with other methods of ULR blocking.
Robots.txt: pros and cons
Advantages:
- Prevents indexing of individual pages, files, and directories.
- The ability to adjust the resolution on the indexing of individual files in a directory, which is closed from indexation.
- Easy to use in comparison, for example, with Robots meta tag.
- Ability to close the entire site from being indexed by specifying the txt disallow directory (folder).
Disadvantages:
- Getting into the secondary index. Pages, closed from indexation, are still likely to appear in Google. In particular, these pages can be found in the sub-index of an SE by using the operator “site: my-site.com” and clicking on “Show hidden results.” The presence of a large number of pages in the sub-index slows indexation and lowers site positions in SERPS (as Google considers that such site has a lot of useless pages).
- Incorrect reading of the file by a search engine. Another significant disadvantage is that Google can incorrectly read the information in robots.txt, so the quality pages can get into the secondary index.
Essential advices
- Always check the presence of necessary pages by “Site” operator.
- Use meta name = «robots» in a head block if you need to close a whole page from being indexed and forbid the crawler to follow links on this page.
- Specify the link rel = «canonical» attribute for pages that duplicate content of the canonical page.
- Remove unnecessary pages that are already in the index of an SE using the GWT “Delete URL-addresses” option.
- Use 301 redirect to join doubles.
- Use rel = «canonical» http-header.

The problem of duplicate pages has always been up-to-date for any SEO-expert. So do not be afraid to experiments, use a variety of options for dealing with doubles, evaluate the results and make conclusions on the basis of your practice, not only on theory.
Robots.txt optioning for WordPress
WordPress contains a large number of service folders that SEs do not need to index. Therefore, make sure that SEs do not spend resources on them. This moment is very important, as sooner or later the robot may not like these strange service files and eventually begin to miss important pages of your site. In addition, when accessing to unnecessary pages, a robot loads your server. Do you want it? Sure, you don’t.
When creating robots.txt, prescribe the necessary instructions subjected to the following formula:
instruction mane – optional space – value,where instruction mane can take the following options: User-agent, Disallow, Allow, Sitemap.
- User-agent robots.txt is used to name a specific search bot that you plan to communicate with. If the instructions are designed for all SEs, specify “*” mark. The following lines contain specific instructions that prohibit or allow indexing of individual sections (directories) and pages.
- Allow and Disallow. Permits and prohibits the indexation of specified sections of the blog. First you need to use “Allow”, and only then – “Disallow”. In addition, there should not be any empty lines between them (otherwise, a robot understands it as an end on instruction).

- Host. It indicates a site mirror that is considered as the main one. Any site is available by several addresses (e.g. with and without “www”).
- Sitemap. It indicates the presence and the address of a sitemap in XML format.
What should you close from indexing in robots.txt?
- Search pages. Yes, it’s somewhat controversial, as sometimes internal site search is used to create relevant pages, but still in most cases open search results could spawn an incredible number of duplicates. Considering the pros and cons, we recommend you to close search pages from indexation.
- Basket and order confirmation page of online stores and other commercial sites, where such pages in any case should not fall in the index of SS.
- Pagination pages. As a rule, such pages contain the same meta tags with dynamic content, which leads to the creation of doubles.
- Filters and comparison pages (for online stores and catalogs).
- Registration and authorization pages. Information showed when registering or entering a site is confidential. Therefore, you should avoid its indexing.
- System directories and files. Each site consists of scripts, CSS tables, some administrative components. These features should also be closed from indexing.
Note: to perform some of the above points, you can use other tools, for example, rel = canonical.
Robots.txt format for WordPress (WP)
Let’s consider the simplest case of standard robots.txt syntax, consisting of 4 lines:
- The first line shows that all downstream instructions are valid relating to all SEs, without any exception.
- A command for crawlers to index directory content and images that have been and will be uploaded on a WordPress site.
- This line reports about the ban on indexing a technical catalog with installed plug-ins.
- The fourth line closes “readme.html” from indexation.
Robots.txt optimization for SEO with the help of popular plug-ins
Remember that the purpose of robots.txt is a recommendation on the effective site scanning and indexing. This file will not protect your site from a comprehensive scan by search engines. For all archive WordPress pages, the best solution, as we see, is to use special SEO plugins – robots.txt makers, analyzers and validators. The latter allows a very flexible adding of robots.txt no index no follow to all “trash” pages. Robots.txt deny (block) all files – pagination pages, doubles, filer pages, etc. – from indexing, so you get clear representing of your site in search.
The next tools can be useful:
Note: in the last CSS versions the administrative WP console, administrator catalog and registration page are already (by default) have prescribed “Noindex” tag. All that you need is to prohibit readme.html on indexation, as well as the directory with the installed plug-ins.
Free online robots.txt file generators and analyzers
All these tools have approximately the same functionality, allowing to generate robots.txt configure folders and/or files indexation:
Hackers never sleep
Readme.html file can be used to determine the current version of WordPress, and this info can help hackers to attack the site. They often use so-called malware requests, allowing finding a specific version of WordPress with a detected vulnerability. In this case, you should use “Disallow” to protect your web resource from possible massive attack.

Together with closing plug-ins catalog, this will greatly improve a security of your site, as there are those who are looking for plug-ins with certain vulnerabilities.
Robots.txt for Joomla
Sample of robots.txt for Joomla 2. 5/3.0:
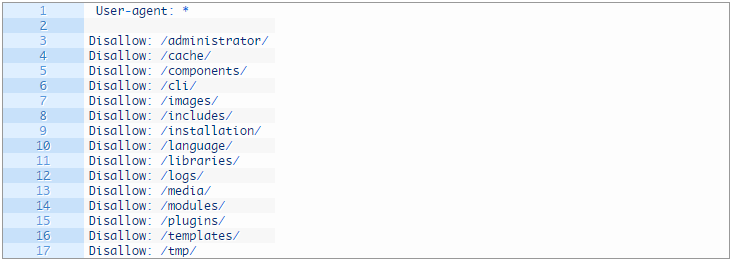
Here the “Disallow” forbids to index all standard catalogs to all SEs (User-agent: *), and allows to index “Print”, “Send email”, “RSS”” Search “,” Registration “,”Password recovery”, etc. The “*” sign means the unlimited number of characters before and after, for example: Disallow: / * feed * prohibits indexing of all links containing the word “feed”.
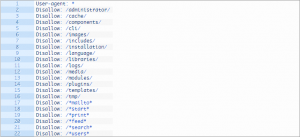
The above code can be somewhat modified for a better SEO:
Robots.txt tutorial for Drupal
Drupal, as well as all the other CMS, provides a robots.txt file. But it needs some edits:
How to fix robots.txt in Drupal?
- Create a backup of the
- Open your robots.txt for editing. If it’s necessary, save the file on PC and open it in a text editor.
- Find Paths (clean URLs) and Paths (no clean URLs) sections:
- Duplicate two sections so that you get four sections – two with the exact URLs and two with no exact URLs.
- Add ‘fixed!’ in the comment to new sections to divide them.
- Remove the slash after each prohibited line in ‘fixed!’ sections. Each section should end like this:
- Save the file, upload it to the server. If necessary, replace the existing file.
- Pass to your website/ txt and accept changes.
How to make a robots.txt file for Magento
Magento websites allow searching for goods by an individual or multiple attributes. This can lead to an excessive number of URLs into Google index. Magento search filter to exclude:

Sure, the filter parameter may vary depending on your site structure.
The basic Magento includes some directories that can be excluded due to a little value to SEs:
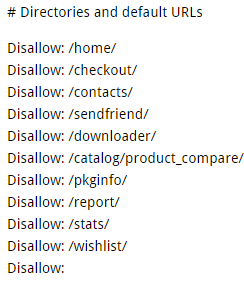
As well as:

Note: Never disallow the /js/ directory, as Google needs it open for access.
You can also exclude from indexing the following Magento files:
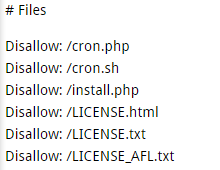
Summarizing
Standard robots.txt options are only a recommendation. In some cases, the SE may not follow the instructions. Thus, constantly analyze and check robots.txt changes and how they affect on indexation. Just spend 5-10 minutes of your life on creating the file and be happy!
Enter URL & See What We Can Do Submit the form to get a detailed report, based on the comprehensive seo analysis.